
The Abstraction Tax: When Generalization Breaks Scalability
The Myth of Universal Design: Engineering for Reality, Not Possibility ...

If you don’t have time to read the full article no worries 🙂 I have prepared the summary of this article with NotebookLM for you.
Link to the video overview & slides
Link to the Podcast: A lively conversation between two hosts
Every system has a budget. Not a dollar budget, an attention budget. A latency budget. A complexity budget. And abstraction is the easiest way to blow that budget while feeling responsible, because generalization has a special kind of charm: it looks like discipline. It looks like you’re designing for scale. It sounds like you’re protecting the future. But most “future-proof” designs are just complexity moved forward in time, prepaid with interest, then handed to everyone who has to build, debug, and operate the system later.
That’s the trade most teams don’t notice until the bill arrives. The first version feels elegant. The second version feels sluggish. The third version needs tribal knowledge. And suddenly the bottleneck isn’t the compute, it’s comprehension. You’re not scaling the system anymore; you’re scaling the amount of interpretation required to use it safely.
This is the “abstraction tax”: the compounding cost you pay, decision by decision, layer by layer, incident by incident, when you abstract before you understand. Sometimes that tax shows up in APIs that become “generic routers,” microservices that turn into “platforms” before they ship value, or configuration frameworks that can express every possibility except the one you need today. And sometimes it shows up in data quietly and relentlessly because the easiest place to hide abstraction is the place nobody wants to refactor once the company depends on it.
So let’s make it concrete. In the world of analytics and AI, the cleanest case study is the data warehouse because it’s exactly where the instinct to over-generalize collides with the reality of scale.
A Data Warehouse Is Not a Production Database
A production database (OLTP) is a nervous system. It flinches in real time. It answers the app’s questions while the user is still mid-tap, and it does it under pressure, thousands of concurrent requests, constant writes, and strict guarantees. In that world, performance is felt. Latency is visible. Consistency is not a preference; it’s a contract. The shape of the data is designed around transactions: what must be written, what must be read back immediately, what can never be ambiguous. A data warehouse (OLAP) is something else entirely. It’s not a nervous system, it’s a memory palace. It doesn’t exist to respond quickly to one person’s click; it exists to let an organization ask big questions and survive the answers. Warehouses consume history. They reconcile. They aggregate. They look for signals across millions (or billions) of rows where no single record matters, but the pattern does. The workload is not “get me the user’s cart in 12 milliseconds.” The workload is “explain what’s changing, where it’s changing, and why it’s changing,” and do it in a way that can be repeated tomorrow without heroics.
This is where teams get tricked, because the words sound similar: database, schema, tables, indexes, models. The tools overlap. The diagrams look familiar. So the mind reaches for the instincts it already has: normalize everything; design for maximum flexibility; keep it generic; avoid creating too many domain-specific tables because that feels “messy.” And in OLTP land, some of those instincts are reasonable. In a warehouse, they can be quietly catastrophic.
The subtlety is that a warehouse doesn’t just store data, it stores meaning. Meaning is not an implementation detail. Meaning is what lets a new engineer ship a feature without summoning an oracle. Meaning is what lets an analyst trust the numbers without reverse-engineering five layers of transformation. Meaning is what lets a business move quickly because the data model matches the way the business actually talks. When you treat a warehouse like a production database, you often optimize the wrong axis. You choose update flexibility over read clarity. You build a schema that can represent anything, because representing anything feels like scale. But scale is not the ability to represent infinite possibilities. Scale is the ability to answer the most important questions repeatedly, correctly, and cheaply, without turning each query into a bespoke expedition.
Generalization in a warehouse often masquerades as maturity:
“We don’t know what the future holds, so let’s keep the model abstract.”
But abstraction is not neutrality. Abstraction is a bet. You’re betting that the future will reward flexibility more than it rewards comprehension. And warehouses almost always punish that bet, because the moment the business starts relying on the data, the primary cost stops being storage or compute. The primary cost becomes cognitive load: how many concepts a human has to juggle to get a correct answer.
That’s why “shape-shifting” is the smell to watch for. In a warehouse, a model that constantly changes shape (because it was built to be generic) doesn’t feel empowering. It feels like fog. It forces every user of the system to do mental joins before they do SQL joins. It turns debugging into anthropology. It makes simple questions weirdly hard, not because the data is complex, but because the representation of the data refuses to be honest about what it is.
A warehouse should make the common path obvious. It should be opinionated about the business, not agnostic. It should be designed for the workload it will actually carry: scans, joins, aggregations, and evolving analytical curiosity. The moment you design it like OLTP (like a machine optimized for small, predictable, transactional truth) you begin drifting toward an architecture optimized for the one thing warehouses cannot afford at scale: ambiguity. And then comes the punchline: you build a data model that can be anything, and you wake up one day realizing it has become nothing - nothing a new person can understand, nothing a query engine can optimize easily, and nothing you can change without fear. At that point, every question becomes archaeology, because you’re not querying data anymore. You’re excavating intent.
And this is the trap: once you accept the wrong mental model, everything downstream “makes sense” in the moment and hurts later. If you believe you’re building for flexibility, you’ll naturally reach for abstraction first, because abstraction feels like keeping options open. But in a warehouse, abstraction isn’t just a design choice; it’s a multiplier on every future query, every future bug, every future teammate trying to understand what the data means. So the real divergence happens early, long before performance dashboards and cost alarms. It happens at the exact moment you decide what you’re optimizing for. One mindset starts by abstracting to protect against an imagined future. The other starts by grounding the model in reality and letting the future earn its abstractions. Let’s look at both.
The Rookie Move: “Is This Generic? Abstract First …”
Here’s the classic rookie story:
“We don’t want to create a table for every domain concept. That’ll be messy. Let’s design a flexible schema that can handle any entity.”
It sounds mature. It sounds like you’re avoiding tech debt. It feels like writing “future-proof” on the whiteboard. But what you’re actually doing is pushing complexity downward, from design-time (where it’s cheap) into runtime (where it’s brutal). Abstraction doesn’t remove complexity. It relocates it. And runtime complexity is the most expensive kind because it multiplies:
more compute per query
more steps per debugging session
more tribal knowledge required to ship anything
more risk of silent data correctness bugs
The Mature Move: “What Are We Solving, What Are We Optimizing For?”
A senior engineer starts somewhere else:
“Before we design the data store, what architectural attributes are we optimizing for and what use cases must this support?”
NOT “What could the future be? Is it generic to support our automation in the future?”. But: What is the workload? Who are the users? What must be fast? What must be correct?
A clean warehouse schema isn’t “flexible.” It’s legible. Legibility scales better than flexibility because it reduces cognitive load - the hidden bottleneck almost nobody measures.
Let’s go through a real world example:
💡 Real World Evidence
A clean, nameable example in the warehouse world is Google Analytics 4’s BigQuery export schema - because it’s basically a giant lesson in what happens when you optimize for maximum generality first, and human queryability later. GA4’s BigQuery export is the cleanest public specimen of the rookie instinct: abstract first, understand later. Google exports a daily events_* table, but the meaning you actually care about - campaign fields, session identifiers, page location, custom dimensions, often lives inside event_params: a repeated RECORD of keys and values whose entire shape can vary by implementation (Ref Link).
In other words: the “schema” is a suggestion, not a rigid contract. And Google’s own sample queries quietly admit what that means in practice. To answer basic questions, you don’t just filter and aggregate - you UNNEST arrays, COALESCE across multiple value types, or even write helper functions just to retrieve one parameter cleanly. The query isn’t analysis anymore; it’s extraction and decoding.
Big teams don’t write thinkpieces about this because it’s fun - they write them because it hurts. TELUS Digital says it plainly: the nested
event_paramsstructure “isn’t ideal if you want to do any analysis,” and then walks readers through the mechanical work of flattening it (Ref Link).And GOV.UK’s analytics team went further: they operationalized the fix. They maintain an official “GA4 flattened table” created from the raw nested export, explicitly because the flattened dataset is “easier and more efficient to query” and should be used for most reporting (Ref Link).
This is what the abstraction tax looks like when it gets real: not philosophy - recurring processing cost and recurring human cost. GOV.UK even monitors BigQuery job spend with a query-cost dashboard and an estimated cost rate (about $7.16 per TiB processed) to spot unusually expensive queries. Because when the model forces heavy UNNEST + reshaping repeatedly, “flexibility” becomes a bill (Ref Link).
Where Over-Generalization Hurts (In Three Quiet, Expensive Ways)
Think of a data warehouse like a zoo. Yes, everything inside is an animal - tigers, deer, chickens, reptiles, etc - but no sane zookeeper says, “They’re all animals (entities), so let’s put them in one giant cage and label them with tags.”. Of course you do that and you won’t find your chickens the next day 😄. You separate them because reality has edges: different diets, different risks, different behaviors, different rules for survival. The enclosures aren’t bureaucracy; they’re the shape of understanding made physical.

Now imagine a zoo that designs for a whale “just in case” - so it pours money into a massive glass tank, fills it with water, maintains pumps and filtration, and builds the whole layout around a creature that doesn’t even exist there yet. That’s what over-generalization feels like in data: you trade today’s clarity for tomorrow’s hypothetical flexibility, and you inherit the cost immediately - operational complexity, weakened boundaries, and a staff that spends more time interpreting the enclosure than caring for what’s inside it (This part also refers to the “YAGNI” principle in XP (xtreme programming). It’s a principle that if you try to build for the future you will end up spending most of your capacity on a future that will never come while immediately adding complexity to your system to support it - Ref Link).

Given these examples, let’s have a closer look where generalization hurts:
1. It breaks the mental map
The first damage over-generalization does isn’t to performance. It is to orientation. If the business has an Order, but the warehouse stores it as a GenericEntityRecord, you’ve introduced a permanent act of translation. Every question now has to be asked twice: once in the language of the business, and again in the language of the storage system.
That sounds small until you feel it in your day-to-day. Engineers and analysts end up carrying two separate realities in their head: the world where there are orders, customers, products, and the world where everything is an entity with a type and a pile of attributes. Nothing is named the way people think. Nothing is where your instincts look first. So even “simple” work starts with reconnaissance:
Where do orders live?
Which key means order_date in this pipeline?
Why does revenue drift only for one segment?
You’re not debugging logic anymore, you’re debugging the map. A domain-shaped table is a signpost. An abstract table is a maze. And the worst part about mazes isn’t that they’re hard once, it’s that you have to solve them again every time you come back.
2. It makes “Ubiquitous Language” impossible
Domain-driven design teaches that teams move faster when they share an Ubiquitous Language - a stable vocabulary that connects product, engineering, and data (Ref Link). When your schema refuses to speak that language (when it insists on being “generic”) you get an organizational split:
business says: “orders”
warehouse says: “entities”
engineers say: “whatever that JSON key is called now”
analysts say: “please don’t touch anything”
“Order” should be an order everywhere. “Customer” should be a customer everywhere. That shared vocabulary is how you avoid building two companies: one that talks in reality, and one that talks in schemas.
But when your warehouse insists on being “generic,” it stops speaking the business’s language and starts speaking its own. The business keeps saying “orders,” while the warehouse talks about “entities.” Engineers stop reasoning about the domain and start reasoning about whichever JSON key happens to represent the concept this week. Analysts learn, quietly, that the fastest way to break a dashboard is to touch the wrong abstraction, so they tiptoe around it. This isn’t a naming problem. It’s a coordination problem. And coordination is throughput.
3. It devolves into a glorified key/value store
Generalization often collapses into one of two patterns:
a. JSON blobs everywhere
And then your “schema” quietly stops being a schema. It becomes “whatever is inside the JSON today,” plus the tribal knowledge of how to interpret it. The database can’t really help you anymore because the database can’t optimize what it can’t see. So every query turns into a little decoding routine:
Now your queries often require:
JSON extraction (extract a path)
type casting (cast it to the type you hope it is)
repeated parsing (handle the nulls, handle the strings-that-should-have-been-ints, and repeat that logic everywhere you need the value)
heavy scans
limited indexing options (and brittle optimization)
The worst part is how this failure scales. The first few queries feel fine because you’re still close to the implementation. But as usage spreads, that same extraction logic gets copy-pasted, forked, and subtly changed. Two dashboards now compute “the same metric” using two slightly different JSON paths. One team treats missing as 0, another treats it as null. Someone changes a key name, and the breakage doesn’t show up as a clean constraint violation; it shows up as a silent shift in numbers. That’s the kind of bug that makes organizations stop trusting data and the outputs extracted from that data
And “performance”? Performance becomes a tax you pay repeatedly. Instead of selecting a column the engine can prune, cache, and optimize, you’re asking it to parse semi-structured blobs at query time over and over, often forcing wider scans than necessary. Indexing and clustering become blunt instruments because the meaningful fields aren’t first-class citizens; they’re buried. You didn’t simplify anything. You just moved schema enforcement from the database - where it can be centralized, validated, and made fast into every query, where it becomes fragmented, expensive, and eventually ungovernable.
💡 Real World Evidence
In practice, the performance penalty isn’t a vague “a bit slower.” It shows up as a very literal multiplication of work:
1. more bytes scanned
2. more CPU burned decoding,
3. and less pruning by the optimizer
Google published a concrete benchmark where the same dataset stored as a JSON STRING versus native JSON changed the amount of data processed from 18.28 GB down to 514 MB (a 97% reduction) just by making the fields queryable without dragging the whole blob through the engine (Ref Link). That’s the schema tax in its purest form: when meaning is buried, the warehouse can’t “read just the columns you asked for,” so it reads and charges you for everything.And even when cost isn’t the headline, CPU becomes the silent killer. JSON paths and casts are not “access,” they’re work: parsing, traversing, coercing types, handling edge cases - per row, per query. Evan Jones measured that accessing JSONB values is about 2× slower than accessing comparable data stored as BYTEA in Postgres (Ref Link). Presto engineers debugging JSON-heavy workloads reported potential improvements of around 3× faster by reducing JSON parsing overhead - meaning the overhead was big enough to be worth fighting at that scale (Ref Link).
And warehouses themselves will tell you the same story in calmer language: Snowflake explicitly recommends flattening key data into relational columns for better pruning and less storage consumption, and notes that values that become strings inside semi-structured columns can be slower and consume more space than proper-typed columns (Ref Link). The pattern is consistent across engines: you don’t escape schema - you just force every query to rebuild it, and then you pay for that rebuild forever.
b. Entity-Attribute-Value (EAV)
EAV is the seductive one because it looks like you did the responsible thing. You didn’t dump everything into a JSON blob; you created tables. You have an entity table, an attribute table, a value table. It feels clean in the way an empty spreadsheet feels clean: infinite possibilities, no opinions, no friction. You can add a “column” without a migration. You can “support any entity.” You can tell yourself you’re building a platform.
But that’s the illusion: EAV doesn’t remove schema, it postpones it until the moment you actually need to do work. And warehouses are built to do work. The first time someone asks a real business question, you discover what you really built: not a dataset, but a reconstruction engine. Every query starts by rebuilding the row you refused to model, pulling “columns” out of a pile of rows. And because each attribute is now a row, the database can’t easily enforce the things that make data trustworthy: strong types, required fields, valid ranges, domain constraints. You can pretend those rules live in application logic, but warehouses aren’t queried by one application, they’re queried by developers, dashboards, notebooks, and ad-hoc exploration. When integrity isn’t in the model, it leaks into the ecosystem as subtle errors and inconsistent interpretations.
The more insidious damage is what it does to the optimizer - and to your ability to reason:
In a normal table, the database can see a typed column, prune partitions, use clustering, and plan joins around stable cardinalities.
In EAV, even simple filters are slippery: first you have to find the attribute rows, then join them back to the entity, often multiple times, and hope you didn’t accidentally multiply results because you’re now joining row-based “columns” across a giant value table. Performance becomes death-by-joins, and correctness becomes death-by-assumptions. What should have been “select orders where status = shipped” turns into “join the value table for status, join again for date, join again for region, … 🤯” and each join is another chance to scan too much, miscast a type, or treat a missing attribute as if it meant something.
And here’s the punchline: teams that adopt EAV usually end up reintroducing the thing they tried to avoid. They build materialized views, denormalized marts, “flattened” tables - anything that turns the EAV ledger back into a comprehensible, columnar shape. Because EAV is flexible in the same way a bag of loose LEGO pieces is flexible: technically, you can build anything. Practically, you spend most of your time searching for the pieces, and the thing you build is never as sturdy as a structure designed with a real blueprint.
💡 Real World Evidence
EAV’s performance penalty isn’t theoretical - it’s the kind of thing that forces grown-up platforms to redesign their DWH once scale stops being a slide-deck word. EAV doesn’t slow you down politely. It slows you down in ratios, and the ratios get uglier right where warehouses live: attribute-heavy questions. The reason is simple physics: EAV turns one business object into dozens of fragments, then makes every read pay the cost of reassembly.
In WooCommerce’s old, meta-heavy order storage (an EAV-like pattern in practice), even the act of placing a single order could write 41+ rows into the metadata table - before plugins add more - so “one order” becomes a small swarm of rows that you now have to scan, filter, and stitch back together forever (Ref Link).
WooCommerce eventually built HPOS (custom, flatter order tables) and published what that tax looked like in numbers: on a test site with ~400k orders, where wp_postmeta had ~1.4 million rows and was about 2GB, creating 1000 orders dropped from ~78.1s in the posts/meta model to ~15.18s with the flatter tables (about 5× faster) and metadata searches sped up from ~0.639s to ~0.053s for 1000-order lookups (roughly 12×), while a “get orders for a customer” query fell from ~0.599s to ~0.016s (about 40× faster) because the system could finally use a real index on a real column instead of spelunking through rows pretending to be columns (Ref Link).
That’s the practical shape of the EAV tax: more rows written per entity (write amplification), more joins or lookups to reconstruct meaning (CPU + latency), and far less ability for the engine to prune and optimize (I/O + cost). And it matches what research has measured in more formal terms too: in EAV/CR schemas, attribute-centered queries - the bread and butter of analytics-style questions - were observed to be ~3-5× less efficient than their conventional equivalents, with the gap widening as data size grows (Ref Link).
Mature vs Rookie: The Same Problem, Two Mindsets
Now, let’s summarize the problems and the senior/mature approach vs. the rookie ones in one single view:
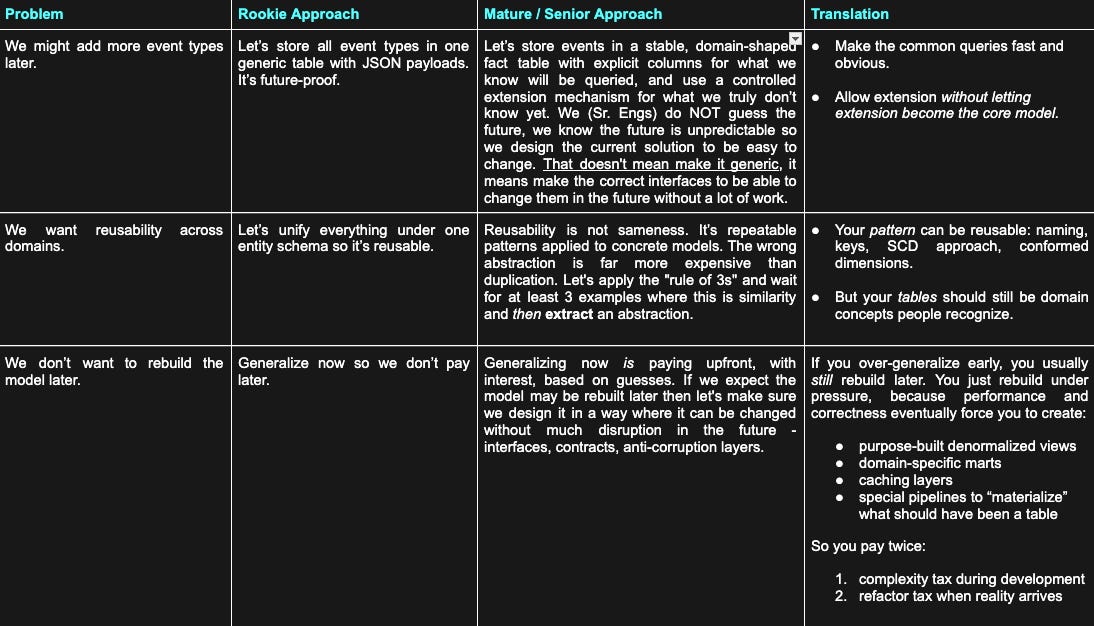
A More Scalable Principle: “Prove It Earned”
Here’s a rule that saves teams years:
Do NOT introduce an abstraction until you can point to the repeated pain it solves.
Because abstraction is not free structure, it’s a permanent decision that future engineers inherit, and it only pays for itself when it eliminates a problem you’ve actually seen more than once.
In a warehouse, that usually means you start by modeling what exists with brutal clarity. You give the business objects real names. You make the grain explicit. You let the system run long enough that reality leaves fingerprints: which questions get asked every week, which joins are always together, which filters are hot, which metrics are constantly reimplemented with tiny differences. Then, and only then, you standardize what repeats. You pull shared logic into a consistent layer because you earned the right to generalize; you’re no longer guessing.
That’s the inversion most teams miss. The scalable move isn’t “design for every future.” The scalable move is “learn the present deeply, then generalize the parts that proved themselves stable (and this is always going to be very limited). Abstractions should be extracted from concrete examples after deeply understanding the domain; don’t predict the abstraction because you will almost always be wrong 😅
Abstraction should be a reward for learning not a substitute for it.
Final Note: What “Good” Looks Like in Practice
A scalable warehouse design tends to have domain-aligned tables because names are not cosmetics, they’re compression. When “Orders” look like orders, a new engineer can land, find the right place naturally, and reason from the business outward instead of spelunking through abstractions. The schema becomes a map, not a puzzle. You’re not just storing data; you’re preserving meaning in a form humans can navigate under pressure.
It also has clear ownership boundaries. Warehouses don’t fail only because of bad SQL, they fail because every team can “just add one thing,” and after a year nobody knows who owns what or what’s safe to change. Bounded contexts and explicit contracts create containment: this dataset is produced by this pipeline, governed by these rules, and consumed through these interfaces. That clarity prevents the slow spread of accidental coupling, the kind where a seemingly harmless change in one corner quietly breaks five consumers in another.
Integrity shows up where it matters because the most expensive bugs in analytics are the ones that don’t crash - they lie. A scalable model makes grain explicit (“one row per order line,” “one row per patient per week,” etc.) and uses constraints, keys, and controlled dimensions wherever feasible, not because the database is your babysitter, but because the warehouse is often the last place you can enforce truth before metrics turn into decisions. Even when hard constraints are limited, the design still reflects integrity: stable keys, consistent deduping rules, and a schema that makes it hard to accidentally double-count.
Performance is designed up front, not bolted on after the dashboards are popular, because warehouses pay for work in proportion to how much data they touch. Partitioning or clustering aligned to real access patterns is the difference between “scan what you need” and “scan the world.” A thoughtful design makes the hot paths cheap: time windows, customer slices, product rollups, cohort analysis, whatever your organization does repeatedly. This isn’t premature optimization; it’s acknowledging the actual physics of analytical workloads.
A scalable warehouse also allows extension, but with guardrails. Real businesses evolve, and you will have edge-case attributes, irregular payloads, and one-off needs. The mature move isn’t pretending those don’t exist or it can all be handled by a single generic system- it’s preventing them from becoming the core model. Extensions should be constrained: clearly typed, documented, versioned, and kept at the edges so they don’t contaminate everything. “Anything goes JSON” is not flexibility; it’s a slow-motion schema collapse that pushes data modeling into every query and quietly makes governance impossible.
And finally, it has shared conventions, because consistency is a force multiplier. Naming standards, conformed dimensions, and canonical metric definitions prevent the most common warehouse failure mode: a dozen versions of the same truth. When “revenue” means one thing, when date keys behave the same way across domains, when customer identifiers are consistent, the warehouse becomes composable. Teams can build without needing a meeting to translate every dataset into every other dataset. You’re not avoiding the future with these choices. You’re building a system that can meet it without becoming unreadable because the real enemy of scale isn’t growth, It is confusion.
Scalability isn’t just about making queries faster or the system more generic to handle everything. It’s about making the system understandable at speed. And that’s why the most scalable data model is often the least clever one: Concrete. Domain-shaped. Obvious.
Because in the end, clarity is the only abstraction that actually scales.